Visualizations with R
Today I’m going to investigate some new data I found on the Chicago Data Portal. The Strategic Subjects List created and maintained by the Chicago Police Department is a list generated by an algorithm created by the Illinois Institute of Technology. The SSL List scores individuals on their probability of being involved in a shooting, either as the victim or offender, so the list is difficult to understand in its entirety because it groups victims and criminals together.
To start, let’s set our directory and load the .csv file, then load the libraries we will be using, in this instance it will be ggplot2 and tidyverse, both very powerful R libraries. Finally, let’s get a preliminary look at the data.
What you should see in your console is a lot of information on the dataset we’re working with. For example, there are 48 columns, or variables, to work with as well as a variety of data types from strings to integers to binary data.
Let’s jump right into the interesting part of this dataset, the SSL scores and graph the distribution of scores. It should be noted that this dataset, straight from the Chicago data portal, is a complete de-sensitized dataset of the SSL scores from its inception in August of 2012 through 2016.
# Plot SSL Scores for Chicago
plot1 <- ggplot(data = ssl, aes(x = SSL.SCORE)) + geom_histogram(binwidth = 5)
plot1 + xlab("SSL Score 2012-2016") + ylab("Count") + labs(title = "SSL Histogram 2012 to 2016") + theme(plot.title = element_text(hjust = 0.5))
We should see a relatively even distributed histogram of SSL scores for 2012 to 2016. It looks like most of the SSL scores are between 200 and 400 with a peak at approximately 325.
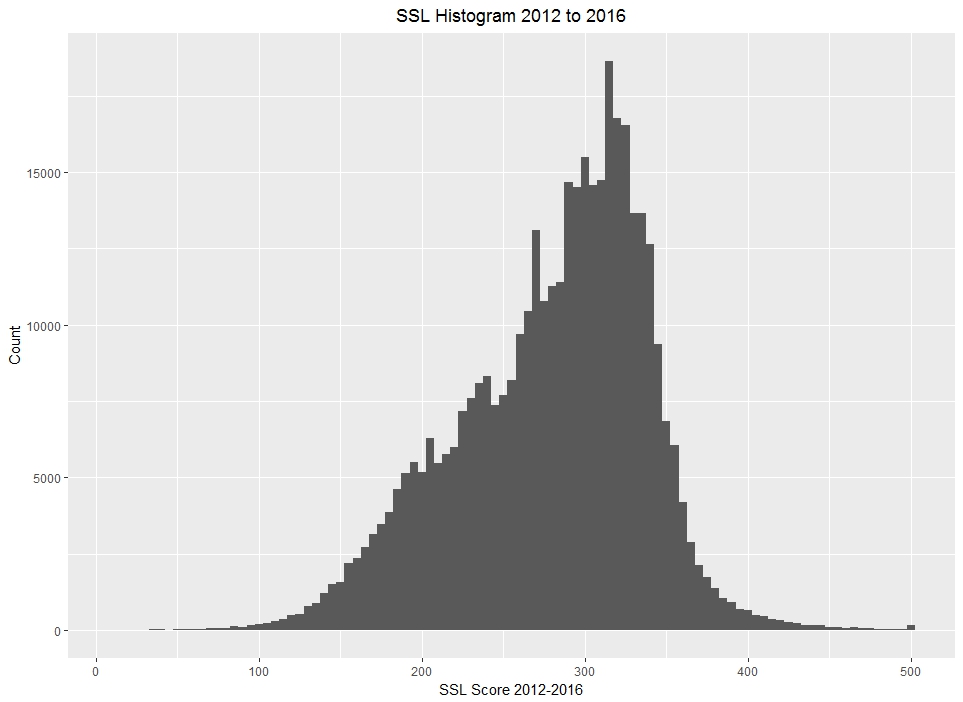
Chicago’s homicide rates and violent crime rates for 2016 are especially prolific in the media and within the city. Let’s look specifically at the 2016 SSL data. Fortunately, in the SSL dataframe is a column called “LATEST.DATE” which indicates the latest date by year of police contact. Let’s subset the data for 2016 and see if it differs from the overall data. First, we need to subset the data for 2016 , then we need to re-plot our new 2016 data.
# subset just 2016
SSL16 <- subset(ssl, LATEST.DATE == 2016)
# plot SSL scores for 2016
plot16 <- ggplot(data = SSL16, aes(x = SSL.SCORE)) + geom_histogram(binwidth = 5)
plot16 + xlab("SSL Score 2016") + ylab("Count") + labs(title = "SSL Histogram for 2016") + theme(plot.title = element_text(hjust = 0.5))
This time, we get a new graph that is specific to the latest date of police contact for 2016. We definitely see some small changes in the histogram but the overall structure of the distribution is the same. I found it interesting that SSL scores equal to 500 saw a significantly large increase to the previous plot.
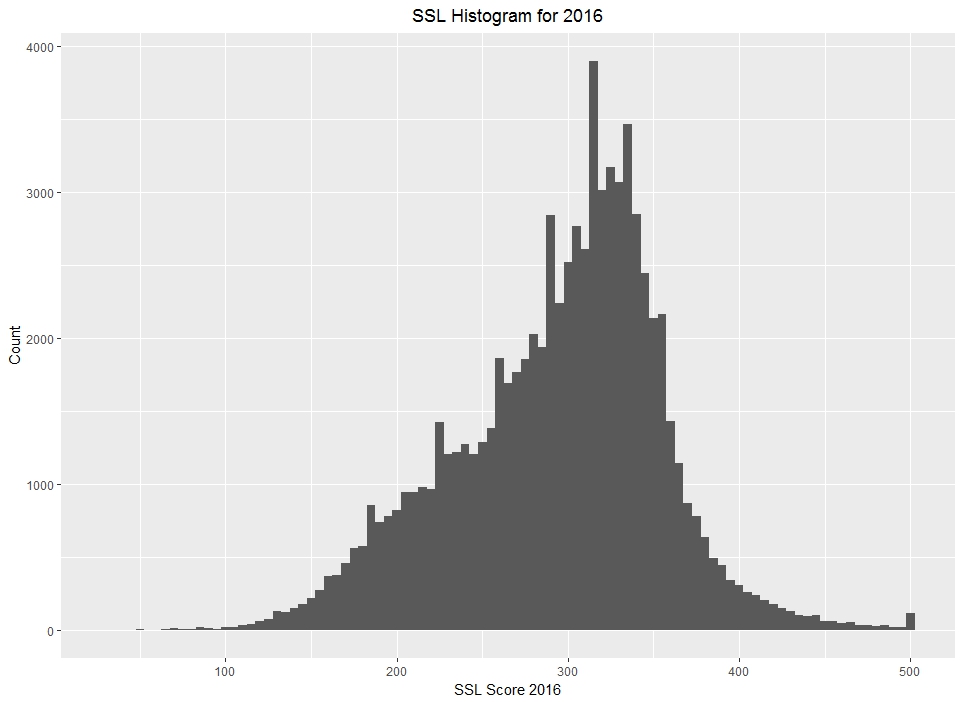
That’s what 2016 looks like, but how have SSL scores difference from 2012 to 2016? Well even though we do not have a great date for when SSL scores were entered, we can see when individuals with SSL scores were last in contact with the police as a proxy for SSL activity by date. For this, we’ll need to total up SSL subjects by year.
# create a list of SSL latest dates by year
ssl_year <- table(ssl$LATEST.DATE)
print(ssl_year)
ssl_yr_table <- as.data.frame(ssl_year)
ssl_table <- ssl_yr_table[7:11, ]
names(ssl_table) <- c("Year", "Number_SSL_Subjects")
# plot
p_year <- ggplot(data = ssl_table, aes(x = Year, y = Number_SSL_Subjects))
p_year + geom_point(aes(color = Year)) + xlab("Year") + ylab("Number of SSL subjects")
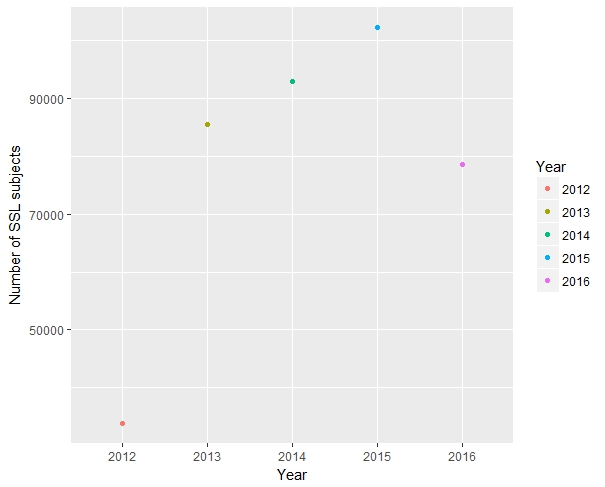
It appears that SSL contact by police has skyrocketed since 2012 and may have dropped a significant amount in 2016. However, for such a short time frame, not much interpretation is appropriate.
love looking at data in a spatial context. Therefore, let’s look at total SSL scores by community area to see if these scores are distributed within the communities we associate with high gang activity, homicides, and violence. Refer back to the column names in the data. We specifically had a variable called “COMMUNITY.AREA”, so we’ll use that for this plot
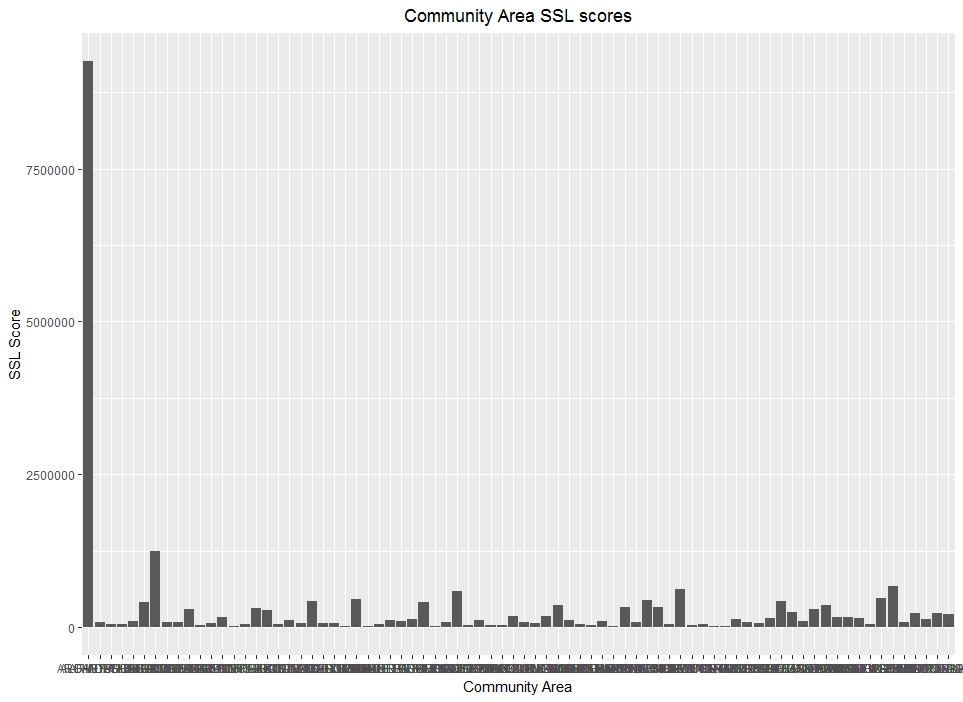
Well this gives an ugly representation of the data for multiple reasons. First, the communities areas are smushed together along the x-axis, making them indistinguishable Also, it looks like we have an issue with the data, one area appears to constitute a huge majority of SSL scores. Let’s tackle this problem one step at a time. First, let’s adjust the graph to see community areas better by tilting the community area identifier.
# plot 2016 SSL scores for Chicago by Community Area
c_area_clean <- ggplot(data = SSL16_clean, aes(x = COMMUNITY.AREA, y = SSL.SCORE)) + geom_col()
c_area_clean + theme(axis.text.x = element_text(angle = 90)) + theme(plot.title = element_text(hjust = 0.5)) + xlab("Community Area") + ylab("SSL Score") + labs(title = "Community Area SSL scores")
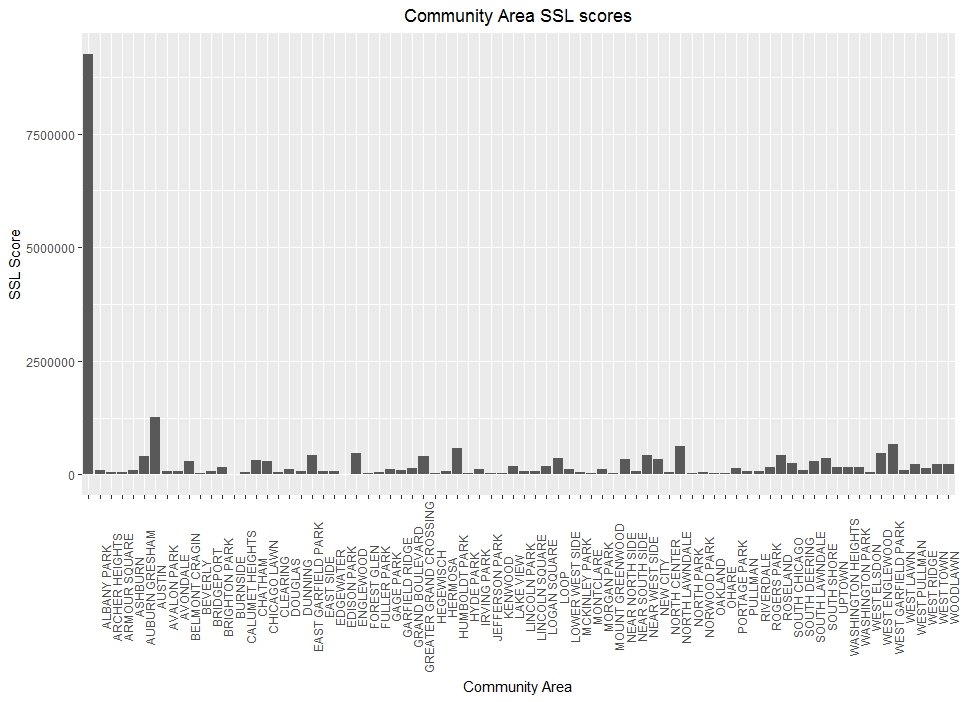
Much better, we can see all the community areas and their respective SSL scores. However, we still have this large column with no community area attached to it. Time to go back to the data.
summary(SSL16$COMMUNITY.AREA)
A summary of community area provides us with a breakdown of the counts for each community area. Right away, we see a blank column ” ” that has over 32,000 SSL scores attached to it. That cannot be right, somewhere along the line CPD wasn’t able to attach a community area to these individuals. With any spatial reference, we need to remove them from the analysis. (If you look at the data, there are also some NA’s in the Community Area column so we’ll remove the empty values and NA values)
# remove data with blank community area
SSL16clean2 <- SSL16[!(is.na(SSL16$COMMUNITY.AREA) | SSL16$COMMUNITY.AREA == " "), ]
Unfortunately, cleaning the data like this really limits our analysis. The total amount of observations for 2016 is reduced from 78,586 to 46,405 after removing SSL values without a spatial reference. However, that shouldn’t discourage us from continuing.
Let’s finish by plotting the newly cleaned SSL scores by community area.
# plot cleaned total 2016 scores for Chicago by Community Area
c_area_clean2 <- ggplot(data = SSL16clean2, aes(x = COMMUNITY.AREA, y = SSL.SCORE)) + geom_col()
c_area_clean2 + theme(axis.text.x = element_text(angle = 90)) + xlab("Community Area") + ylab("SSL Score") + labs(title = "Community Area SSL scores")
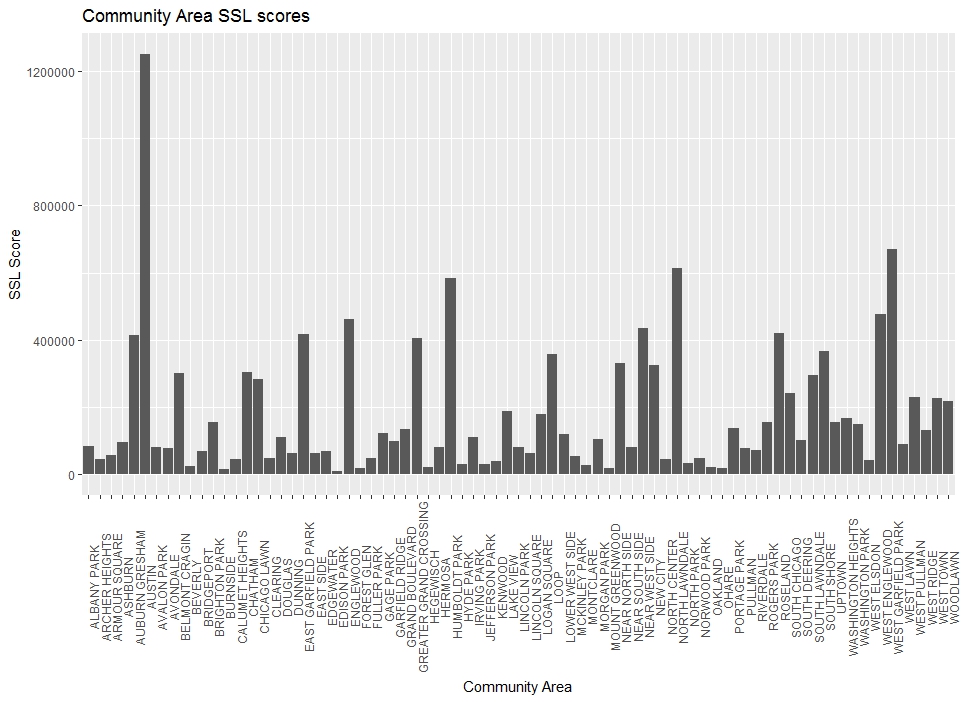
What we end up with is a cleaned dataset of SSL scores, totaled, for each Chicago community area. From the graph, we can see that one community area in particular, Austin, is responsible for a large majority of SSL scores compared to all other community areas. The next closest community area appears to be West Garfield Park. If we go back to our summary of community areas, this makes sense because Austin holds the largest count of SSL subjects at 4122 and West Garfield Park has the second highest count of subjects at 2295.
This was a very basic exploratory analysis of some very important Chicago public safety. Hopefully, this post sheds some light on how powerful and quick plotting and graphing in R is, but more importantly that further analysis into CPD’s SSL scores is critical to understanding how to best utilize them.
Until next time,
Kevin