Background
In my pursuit of professional growth and skill development, I have recently turned to design theory, visualization best practices, and authors who are held in high regard for these principles. One such author I have particularly enjoyed is Edward Tufte. After reading “The Visual Display of Quantitative Information”, I was left with a dozen or so bookmarks of charts and visualization examples to replicate or incorporate into future work. Leveraging my backing in Tableau and R (& my growing skills in Power BI) and a wealth of data viz opportunities from community challenges including #MakeoverMonday, #RWFD, and #TidyTuesday, I thought this would be a perfect excuse to incorporate the lessons learned from Tufte into my work, blog about the development of visualizations, and reflect on the practicality and use-case of each particular lesson from Tufte (and others!).

Sparklines and Datawords
For the seasoned data analyst or data visualizer out there, I will venture to guess the concept of sparklines and datawords will not be a foreign concept. While the term Tufte uses may be new, this type of visual goes by many names (for example callout numbers, callout boxes, dashboard cards, visual annotations) and is ubiquitous with business dashboards and sporting visuals, to name a few. What I found compelling from Tufte’s writing was the extent to which these visuals can derive meaning, capitalize on context, and push the boundaries of data presented within a relatively small footprint. I’ll go into detail on what I mean by this in the next section.
At its core, sparklines and datawords are, as Tufte puts it, “data-intense, design simple, word-sized graphics”. Sparklines and datawords can simply compliment a textbox or act as standalone visual to call attention to a single measurement, but they can also be used as a comprehensive visualization in the form of a small multiples visual or combined with a large table of data.


When I encountered this concept in Tufte’s book, I knew I wanted to capitalize on the effectiveness of sparklines and design an entire dashboard around this idea. Fortunately, #MakeoverMonday’s weekly challenge covered global cash crops and the dataset provided had a variety of contextually relevant and interconnected dimensions. Additionally, Tufte provided an example of a visualization on forecasting economic indices in his book (page 180) with a template which I found to be perfect for this week’s #MM challenge.

After close examination, this visual has a few important characteristics I plan to replicate in a Tableau dashboard. Namely:
- Some kind of baseline or average value/dataword established across all dimensions (i.e. the black panel)
- Columns of datawords arranged ascending/descending based on the baseline value - in this example, based on how close they were to the baseline forecast
- Standardized containers for each dimension and value across the visual
- Descriptions or legends placed organically in blank areas caused by the arrangement of the datawords
Building a sparkline and dataword dashboard
Up to this point, I have covered the why, the what, and the so what; now we will cover the how.

Taking advantage of the global cash crops dataset posted to dataworld for #MakeoverMonday, we can begin building this dashboard, making sure to incorporate as many of the observations from the visual above.
The global cash crops dataset provides an advantageous structuring of data for our visualization. It contains a region column for 5 of the 6 continents (excluding Antarctica) plus a global category, an element column describing the type of crop resource measured, a year column, and a value column (including a unit of measure). Thus, we can arrange the columns based on element (crop production, harvest, and yield) broken up by region, and described by year and value/unit. Additionally, while no baseline or target to compare regions was provided, we can compare each region against the global value (more importantly, against the global percent change). Furthermore, since each visual is standardized in its size, visualization, and filters, with small variation to the dataset dimensional values, we need only create a template and replicate it across the dashboard.
Starting with the template, I will need one sheet with a dynamic text box and value for the dataword and one sheet for the sparkline. The dynamic text box is simply the ‘element’, ‘area’, and ‘value’ dimensions - though the ‘value’ is a percent change of the current year from the overall average, respective of the ‘area’ and ‘element’.
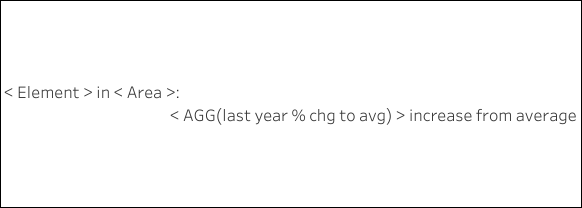
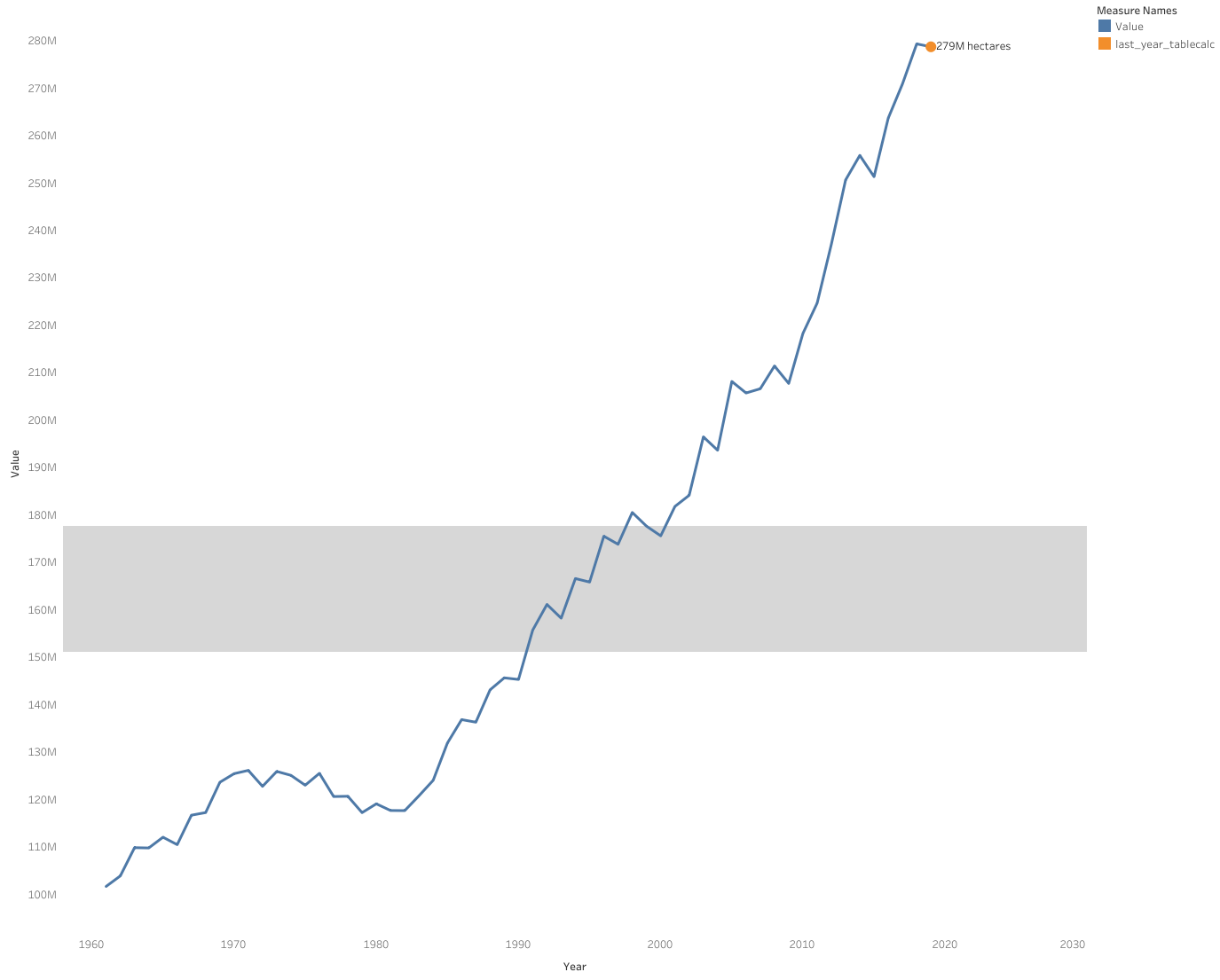
With the easy part out of the way, I can now move on to the sparkline visual. You’ll notice the example Tufte provided in his book was simply an arrangement of datawords. I am much more interested in including both the dataword and sparkline as the sparkline offers a historical, time-series context that should be useful with this dataset.
The sparkline visual I went for is a simple line chart with a large end-point dot and a 95% confidence interval band. The pronounced dot at the end of the line signifies the last date value of the line chart and also helps the viewer evaluate each respective line chart’s historical trend as well as compare across sparklines of the same dimension(s). The confidence interval, on the other hand, provides this incredibly powerful yet simplistic visualization of a normal range of values and the reader can quickyl evaluate whether a year or time period has performed above or below that range.
The end-point dot ‘trick’ is simple to accomplish in Tableau by utilizing the dual-axis functionality of a sheet (I plan on learning how to do something like this in PowerBI very soon!). Arguably the most difficult part of this viz is identifying the last point in the line chart. There are numerous ways to write this calculation but I found this IIF (i.e. if and only if) table calc to work best and most succinctly.
IIF(LAST()=0, SUM([Value]), NULL)Once the dual axes are combined and synchronized, you should end up with a sparkline template like this:
With the dataword and sparkline templates completed, the tedious work begins. This viz should end up having 36 separate sheets (3 rows of elements, 6 regions, and 2 vizzes for each region - dataword and sparkine) based on the original dataword and sparkline templates. The final touches for my viz included a title, a description, an interactive legend, or how to read section, and a footer with my Twitter signature and data source. In keeping with Tufte’s example, I added a background to the worldwide dataword and sparkline visualizations across all 3 element dimensions to signify the baseline established by the global values.
Here is the final product:
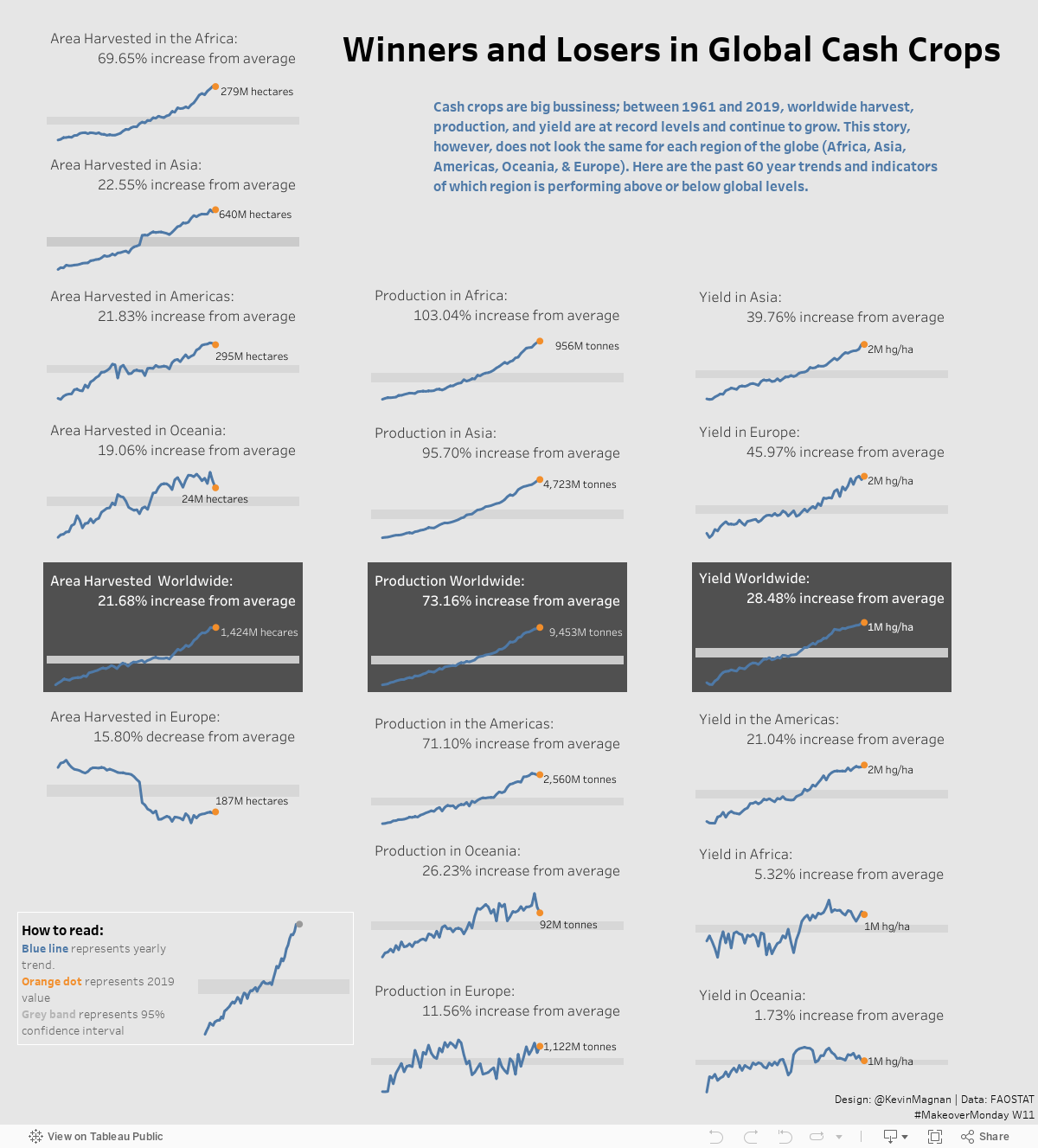
That’s going to finish up my first blog post of this mini-series! I will be following up with a second post on a dot-dash-plot very soon!